
Übersicht für Data Warehouse und BI
Welche Vorteile bieten Modelle und was kann die Methode Data Vault hierbei leisten?
Im Gespräch mit Kunden über BI-Lösungen begegnet man häufig dem gleichen Phänomen. Es besteht ein großer Wunsch nach Übersicht über die komplette BI-Lösung. Nicht nur über die Datenmodelle selbst, das ist unstrittig, sondern vielmehr bei Modellen zur Datengenese. Liegt hier doch ein wesentlicher Teil komplexer Logik, dessen Verständnis sich direkt auf die Lebensdauer der Lösung auswirkt. Je besser die Logik der ETL- bzw. ELT-Prozesse verstanden ist, desto länger braucht es, bis ein Re-Design nötig wird. Gleichzeitig besteht eine gewisse Furcht vor Mehraufwänden. Der Wunsch nach Übersichtlichkeit steht in direktem Konflikt mit den knappen Ressourcen. So stehen viele BI-Verantwortliche vor dem Dilemma, entweder heute mehr zu investieren oder später die komplette Lösung neu bauen zu müssen.
Das ist eine schwierige Entscheidung, die zu fällen sich vermeiden lässt. Ein gutes Modell für Data Warehouse und BI muss mehr bieten als nur eine Übersicht. Es muss gleichzeitig auch seinen Teil zum Entwicklungsfortschritt beitragen. Das Modell ist somit nicht nur Selbstzweck und wird das Modell weggelassen, ist auch der nächste Schritt mehr Aufwand. Wenn man also ein Datenmodell erstellt, erhält man neben der Übersicht auch die Datenbeschreibungssprache DDL (Data Definition Language) für das Datenbankschema. Ohne Modell müsste man es von Hand pflegen.
Mit Data Vault mehr aus dem Modell herausholen
Mit Data Vault kann man ein solches Modell erstellen, welches den nächsten Entwicklungsschritt unterstützen bzw. komplett generieren und so beschleunigen kann. Data Vault besteht aus Modellierungsmethode und Architektur. In der Architektur erfolgt die Konzentration auf die Bereitstellung früher Ergebnisse. In der Modellierung liegt der Fokus auf der Flexibilität und Änderungsfreundlichkeit. Änderungen sind immer lokal begrenzt. Damit erlaubt einem Data Vault, schnell Ergebnisse vorzustellen und diese dann inkrementell zu verbessern. So kann die Kraft agiler Vorgehensweisen in das Core Warehouse gebracht werden, aber auch traditionelle Ansätze profitieren davon.
Um möglichst früh komplette Ergebnisse bereitzustellen, trennt Data Vault die Frage der Datenintegration von aller sonstigen Logik wie der Datenkonsolidierung, Maßnahmen für die Datenqualität oder Dublettenbereinigung. All die komplexen Verarbeitungsschritte werden in einem Extraschritt innerhalb des Core Warehouse erledigt. Dieser Teil des Core Warehouses wird als Business Vault bezeichnet. Die Datenintegration kann so standardisiert werden und dieser Standard lässt sich dann automatisieren.
Exkurs: Data Vault Modellierung
Data Vault ist eine spezielle Datenmodellierungsmethode, die irgendwo zwischen dritter und vierter Normalform liegt. Die Geschäftsobjekte werden als Hub modelliert. Der Identifizierer für dieses Geschäftsobjekt wird als Business Key bezeichnet. Die Attribute, die diese Geschäftsobjekte beschreiben, werden in Satelliten abgelegt. Die Transaktionen sind Links, die die Geschäftsobjekte bzw. Hubs miteinander verknüpfen. Auch die beschreibenden Attribute des Links werden in einem Satelliten abgelegt, siehe Abbildung 1.
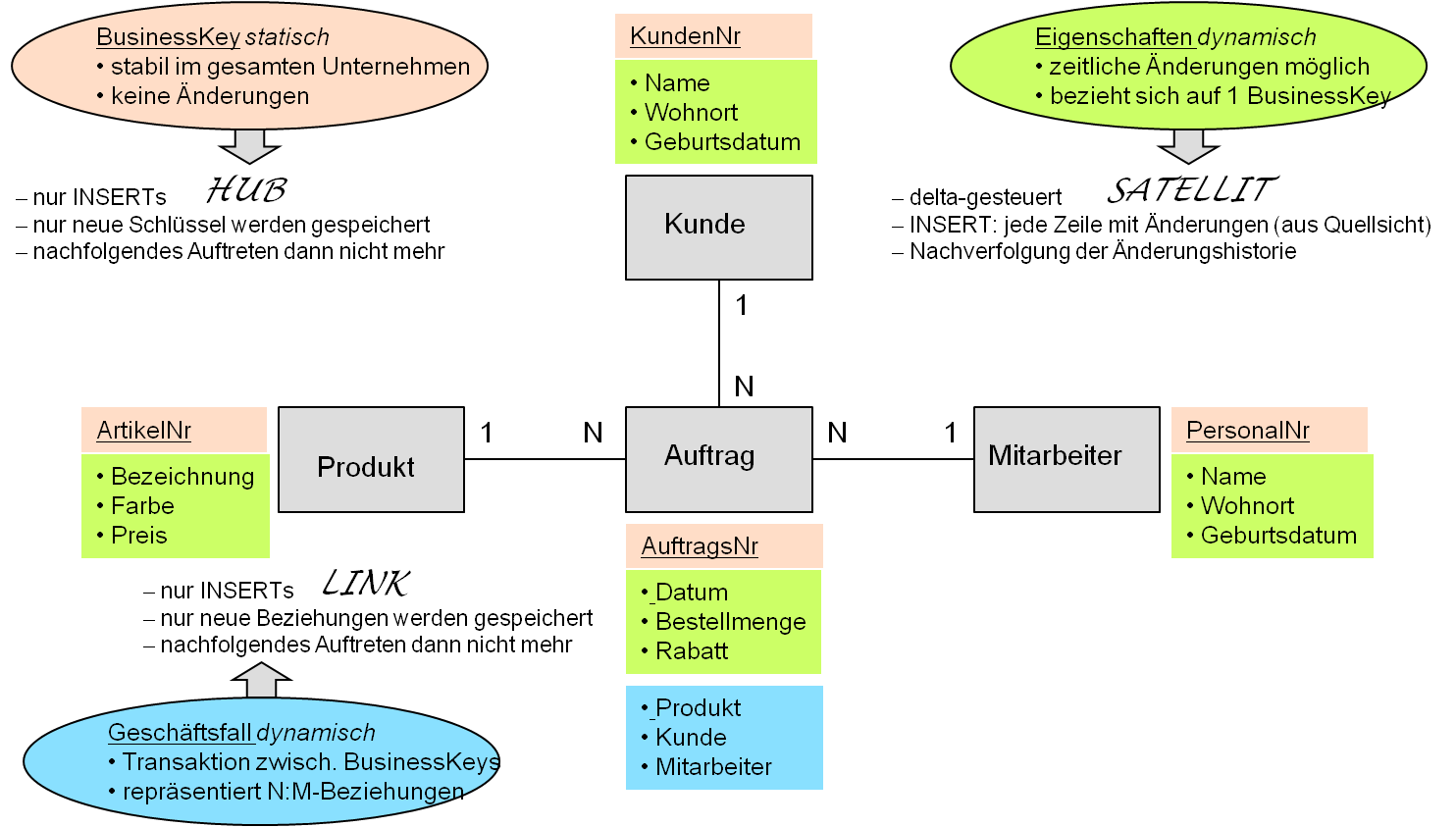
Abbildung 1: Data Vault-Schema, Quelle: MID GmbH.
Das so entstandene Modell lässt sich automatisieren, da die Befüllung nach dem immer gleichem Muster abläuft. Jeder Hub, Link oder Satellit wird mit jeweils einem SQL-Template gefüllt. Man muss jeweils nur die Metadaten eintragen.
Wenn man diese Methodik anwendet, hat man schnell ein Modell der Core Warehouse-Schicht und auch wenn die komplexe Logik noch fehlt, kann man diese Daten bereits in einem Data Mart darstellen. Das Ergebnis kann früh dem Fachbereich präsentiert werden, welcher die Daten im Rohzustand sieht, und auf dieser Basis bessere Anforderungen formulieren kann.
Doch wie kann man hier mit Modellen schneller arbeiten? Und wie liefern hier Modelle einen Mehrwert?
Automatisierung von Data Vault im Modell
Schaut man sich die notwendigen Arbeitsschritte für die Erstellung eines Data Vault-Modells an, so müssen auf Basis der Ladeschicht:
- die Attribute nach Hub, Link und Satellite klassifiziert werden,
- die jeweiligen Entitäten erstellt werden,
- die Attribute den Entitäten zugewiesen und
- die Beziehungen zwischen den Entitäten gezogen werden.
Damit steht das Modell. Anhand von Abhängigkeiten zwischen Ladetabelle und Data Vault können die notwendigen Metdaten gewonnen werden, um die SQL-Templates für die Befüllung des Data Vault zu gewinnen.
Für diese Arbeiten gibt es nun zwei Möglichkeiten. Ein häufig verwendeter Ansatz ist die Auszeichnung der Attribute in der Ladeschicht und die Generierung des kompletten Data Vault-Modells. Dies entsteht komplett per Knopfdruck, was aber eine Reihe von Nachteilen hat:
- Bis alle Attribute ausgezeichnet sind, müssen viele Mausklicks erfolgen, ohne dass man einen Erfolg sieht.
- Das entstandene Modell ist groß und muss nun noch kontrolliert werden, Fehler bei der Attributkennzeichnung sind schwer zu finden.
- Für die nächsten Versionen, für jede Änderung muss das komplette Modell noch einmal erstellt oder kleine manuelle Arbeitsschritte hinzufügen werden.
Ein anderes Vorgehen ist folgendes: Mit einem neuen Werkzeug, dem sogenannten Beamer kann man die Attribute in die DWH-Schicht kopieren. In einem Arbeitsschritt entstehen so die Entitäten und Attribute für das Data Vault-Modell sowie die Abhängigkeiten zur Ladeschicht. In einem zweiten Schritt müssen nun noch die Beziehungen zwischen den Entitäten gezogen werden.
Automatisierung von Data Vault aus dem Modell
Mit diesem Ergebnis, den Schemata der Lade- und der Data Vault-Schicht sowie den Abhängigkeiten zwischen den beiden Schichten kann man nun die Befüllung des Data Vault generieren. Entweder in dem damit das Mapping in ETL-Prozessen generiert wird, oder noch einfacher, in dem SQL-Templates mit diesen Daten befüllt werden.
Mehrwert aus Modellen
Nun wird deutlich, dass etwas fehlt, wenn das Modell nicht erstellt wurde. Mit der Generierung der Befüllung kann man den kompletten nächsten Entwicklungsschritt auf einen Bruchteil des ursprünglichen Aufwandes reduzieren. Diesen Gewinn an Zeit, den man bei der Erstellung des Data Vault erzielt, kann nun in die Modellierung des Business Vault gesteckt werden. Im Business Vault werden die komplexen Verarbeitungsschritte vollzogen. Hier lohnt sich der Aufwand für eine komplette Beschreibung der Arbeitsschritte in verständlicher Prosa. Mit dieser Darstellung ist die spätere Wartung erheblich einfacher. Wie man in diesen Fällen dennoch ein komplettes Lineage über alle Schichten hinweg realisieren kann, wird im nächsten Artikel gezeigt.
Durch den Einsatz von Data Vault und eines Modellierungs-Tools kann man
- inkrementell und
- agil entwickeln,
- flexibel bleiben,
- die Übersicht behalten und
- die Entwicklung beschleunigen.
- Auf Basis eines standardisierten Vorgehens,
- in welchem die einzelnen Schritte automatisiert abgearbeitet werden.
Wäre das nicht auch etwas für Sie?
Kontakt: Michael Müller, Principal, MID GmbH, m.mueller@mid.de
- keine Angebote auf Ihrem Merkzettel