
Technologische Umsetzung von Business Intelligence-Systemen
Aus welchen Bestandteilen setzt sich ein BI-System zusammen, und welche Funktionen erfüllen diese Teilsysteme?
Laut der Definition von Kemper und Baars ist Business Intelligence (BI) ein „organisatorischer Gesamtansatz und somit stets unternehmensindividuell zu konkretisieren und auszugestalten“. Dies impliziert, dass eine individuelle Ausgestaltung immer auf der Basis eines generischen Ordnungsrahmens aufbauen muss. Dieser wird hier zugrunde gelegt und dient gleichermaßen als Strukturierungsgrundlage für die folgenden Ausführungen. Zu den vier Bestandteilen des Ordnungsrahmens zählen:
- Datenquelle
- Data-Warehouse-System
- Analyseschicht
- Präsentation
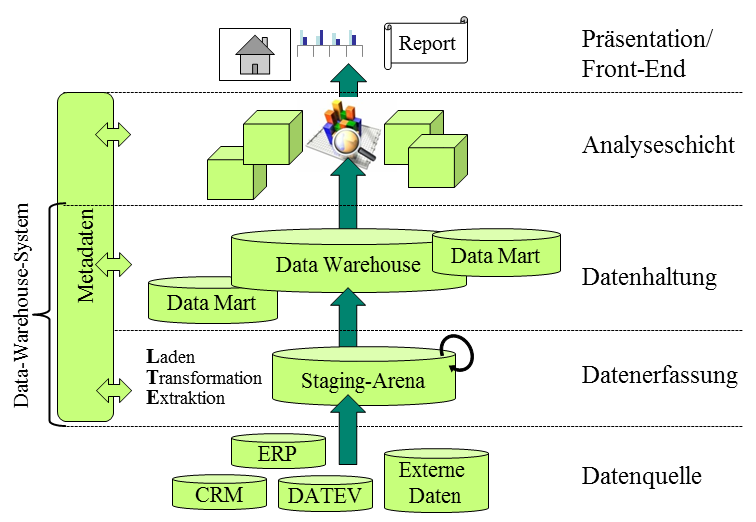
Abbildung 1: Visualisierung Ordnungsrahmen
Datenquelle
In der Literatur gibt es keinen einheitlichen Konsens, ob die Datenquellen als Teil der BI-Architektur gesehen werden können oder eher als vorgelagerte Quelle für die Architektur dienen. Kemper et al. beschreiben sie als vorgelagertes Quellsystem, wohingegen die Erläuterungen und Grafiken von Burmester so zu verstehen sind, dass er sie als Bestandteil der BI-Architektur sieht. Die Integration der Datenquellen scheint jedoch sehr sinnvoll, da es eine Datenbasis geben muss, um auf deren Grundlage Auswertungen zu machen. Diese Datenquellen setzen sich zum einen aus ERP-Systemen zusammen. ERP-Systeme dienen der integrierten Abwicklung von meist operativen Prozessen in einem Unternehmen. Zum anderen werden die Daten von Systemen generiert, die dazu dienen, das gesamte Unternehmen zu unterstützen, wie zum Beispiel Supply-Chain-Management (SCM-) Systeme. Es handelt sich also um externe sowie interne Systeme, die sowohl strukturierte als auch unstrukturierte Daten enthalten.
Data-Warehouse-System
In den meisten Unternehmen sind die operativen Systeme historisch gewachsen und haben große Datenmengen erzeugt. Leider kommt es oft vor, dass die Daten nicht einheitlich sind, was zur Folge hat, dass diese Daten nur eingeschränkt oder gar nicht entscheidungsunterstützend mit einbezogen werden können. Dieses Problem erkannten 1988 auch Devlin und Murphy, die sich als Erste mit dem Thema Data Warehouse (DW) bei der IBM beschäftigten. Es war jedoch Inmon, der drei Jahre später als erster Data Warehouse als „themenorientierten, integrierten, beständigen und zeitbezogenen Datenspeicher für die Entscheidungsunterstützung des Managements“ definierte.
Der erste Teilaspekt eines DW, gemäß der Abbildung oben, ist die Datenerfassung. Hier werden zunächst die operativen Daten aus den Vorsystemen extrahiert und ggf. zwischengespeichert. Anschließend werden die Daten in das Format des DW transformiert, simultan bereinigt und aggregiert. Beim letzten Schritt werden die so erzeugten Daten in das DW geladen. Dieser Prozess wird aufgrund des Vorgehens Extraktion, Transformation und Laden auch als ETL-Prozess bezeichnet und beschreibt die Integration von internen betriebswirtschaftlichen Daten und anderen in- und externen Datenquellen hin zum DW.
Der zweite Teil des Data Warehouse-Systems besteht aus der Datenhaltungsschicht. Diese Schicht wird durch die Datenbanken gebildet, bei denen die Daten so gespeichert werden, dass sie jederzeit gesichert sind, auch bei unerwartetem Ausfall des Systems. Als Kern-Data-Warehouse werden DWs beschrieben, bei denen die Daten nicht aggregiert, sondern sehr detailliert und normalisiert sind, was bei konsistenten Daten eine genauere Analyse ermöglicht. Von einem zentralen DW wird dann gesprochen, wenn man im Unternehmen nur ein DW angeschlossen hat. Eine andere Art der Speicherung der Daten sind sogenannte Data Marts (DMA). Diese sind meist ebenfalls durch historische Ursachen entstanden und stoßen somit auch sehr schnell an ihre Grenzen. Lediglich bei immer wiederkehrenden Abfragen ist es ratsam, DMA anzuwenden, weil damit schnellere Abfragen möglich sind.
Analyseschicht
Die Aufgabe der Analyseschicht ist die Analyse und Aufbereitung der Daten aus dem DW und die anschließende Weiterleitung der Daten an die Präsentationsschicht. Die Analyseschicht lässt sich grundsätzlich in zwei unterschiedliche Systemarten unterteilen. Diese werden meist als BI-Basissystem und konzeptorientiertes BI-System beschrieben. Detailliertere Informationen zur Analyseschicht finden Sie im Artikel Analysesysteme in der Data Warehouse Architektur.
Präsentationschicht
Hierbei geht es um die Visualisierung des in den anderen Schichten kumulierten Wissens. Sie wird auch als Front-End bezeichnet und wird von den Endanwendern direkt verwendet. Hierbei ist es zwingend erforderlich, wie von Meyer beschrieben, verschiedene Visualisierungstechniken anzuwenden, um dadurch die Wahrnehmung der Informationen zu erhöhen. Ein weiterer wichtiger Aspekt ist, dass die Informationen in einer Art und Weise dargestellt werden, die man gewohnt ist. Aus diesem Grund werden häufig Instrumententafeln wie im Auto (Dashboarding) oder Ampelfarben verwendet, da man solche Informationen schnell verarbeiten kann.
Kontakt: Oliver Tovar, Consultant Rödl Reporting, Rödl Dynamics AG, Oliver.Tovar@roedl.com
- keine Angebote auf Ihrem Merkzettel